 _
_Viewed 6682 times | words: 2690
Published on 2021-10-10 16:40:00 | words: 2690

Yesterday released an update to my recent (September 2021) Italy's PNRR - funding and coverage / funding timeline from the European Council assessment as of 2021-07-08.
This article is going to be a (relatively) short article, focused on few elements:
_a recap of my approach to data and (self-assumed) data-role on PNRR
_what's new in that PNRR-related dataset on funding and coverage
_where are we now on the path to the implementation of the PNRR
_humble suggestions for others interested in observing PNRR delivery
_next steps: the end of the beginning
A recap of my approach to data and (self-assumed) data-role on PNRR
Let's just say that, based on my experience on first reading number crunching for political purposes (European Federalist integration advocacy, starting when I was 17), then on logistics and field exercises in the Army (for fun, spent a significant chunk of my spare time and R&R in libraries to develop a software - unfinished due to incompatibilities - to replace tables we used to do what I could call "weather forecast for artillery") as well as scheduling on a daily basis allocation of people to tasks and associated rearrangements due to plan meeting reality, and then few decades on business number crunching to support senior management decision making...
...I found myself often on the receiving end of poor quality information that had filtered up polluting choices with misleading information.
It was not sloppiness or poor quality work, often: it was the result of a misallocation of knowledge and tasks.
Specifically: those who were to collate, assemble, filter, process data so that could enter the point where would become part of the "knowledge supply chain" leading to decision makers had no clue whatsoever on the meaning of data- just assumptions.
As I was told once by a CFO who had been a manager in audit, it was the same process I saw often in other industries: those who have time (really meaning: those whose time is cheap enough to be spent liberally on mundane data-cleaning tasks) lack the understanding of the overall picture, while those who understand the overall picture (or, at least, a specific domain) usually find more productive ways to allocate their own time (e.g. on the "interpretation" side), and "barrel downstream" the skills and tasks to filter the information.
When the quantity of data was minimal, discrepancies could be "spotted" also in charts etc resulting from that "tainted" data, by those with higher levels of understanding.
But when you have inordinate amounts of continuously updated data, a different approach is needed, as I saw (and applied) already in the late 1980s (if curious, have a look at the ConnectingTheDots book series- you can read them also for free online).
Jumping forward.
The dataset sharing since 2019 was just an add-on to my knowledge/ideas sharing started in 2007, when I prepared to settle in Brussels, where I lived since 2005, after living in UK (but working also in France and German Switzerland).
As I shared within both the DataDemocracy concept page and the article series CitizenAudit, my approach on the PNRR is quite simple: using the experience built since the 1980s across multiple industries on both cultural/organizational change and business number crunching...
...to extract from the #NextGenerationEU, #RRF, and of course #PNRR documents information that can be used by those who have a more "vertical" (by industry, domain, analysis target, or even political affiliation) interest.
So far, the idea worked, looking at the readership numbers and contacts, considering that I have zilch budget for advertisement (on purpose), and, after the end of the COVID19 lockdown and side-effects, when I started working (mid-July) on another mission as PMO in Italy, have time to work on it only in my limited spare time.
A consequence of my return to work and live full-time in Italy in 2012 was that I decided that, beside articles, it made sense to expand some concepts into mini-books, that could use, as I did in the past for "position papers" that wrote on various business processes and approaches or technologies, in my activities.
As an example, before brainstorming sessions, or in projects where some roles were not filled, in order to share a "common ground", since the 1990s, when I was engaged either as management consultant or project/etc manager
...I first gave books (not those that I wrote- purchased multiple copies of books that I assumed could be useful),
...then shared articles from an e-zine on change that I had published 2003-2005 (BusinessFitnessMagazine.com, now on hold pending a repositioning),
...or even position papers that I had prepared for future uses in my own activities (generally, up to 1/4 of my revenue plus time went into "exploratory" projects to test new ideas or develop and test prototypes of business software and services).
While in Brussels, over a decade ago I was actually asked to contribute my ideas on the use and impact of social media (I registered the concept on WGA, before submitting my concept, to be able to keep working on it after the contribution), for a company book for marketing managers on the integration of social media within the corporate marketing mix, and an evolution of that was released within two books, one in English, and one in Italian, that is visible within the "strumenti" section.
Therefore, when I was asked earlier this week about my cost/benefits analysis on the Italian #PNRR, I replied that my current scope is more limited, to the preparation of datasets that reorganize information, while the cost/benefits analysis (that would require "vertical" competencies) is a long-term project that I will have time to tackle with between now and 2026.
And, frankly, I will focus on just some of the missions, those where, for the time being, either I have or I can have access to the relevant "vertical" competencies within the constraints of my budget.
Reason? To retaining absolute creative and analysis freedom- no small feat, in a "tribal" country as Italy is: but I belong to no tribe, and I never get tired of repeating that I am bipartisan, i.e. I cannot accept the Italian concept of redesigning laws and regulation to suit your own purposes or even assumptions that "we are good".
It sounds really old-style political theorist and organizational analyst: but I think that laws and regulations should transcend parochial interests, as the structural stability of the social fabric (what in Italian we call "la tenuta"- the ability to hold it together, this fractured, tribal, quarrelous society of ours) is more relevant.
Laws are obviously a social construct designed by consensus and balance of power (inasmuch I like "A Theory of Justice", I am quite pragmatic about the actual implementation (and motivation thereof), when it comes to social reforms.
For everything else, my interest is limited to the overall "vision" (how I hate that over-inflated word) and the implementation process- while, of course, looking at the numbers and impacts.
As any initiative of this magnitude, no matter how "business-like" or "business-oriented" is presented to be, is a political framework and more than a little bit of social engineering.
Hence, another bit of my approach to #NextGenerationEU, #RRF, #PNRR.
For the initial phase, looked at the preliminary documents from Brussels and their evolution, i.e. before the actual starting size and initial distribution between EU Member States.
Then, started sharing online, both on Kaggle within the datasets and GitHub, the Italian side of the process (i.e. proposals presentations from civil society to the Italian Parliament) first, then the EU-side.
I used GitHub to share mainly the Italian side of documents up to the approval by the Italian Parliament, but for the "number crunching" side (e.g. amounts and timeline) found more interesting to do something else.
The 6 missions are shared, but the components and "commitments on deliverable" will obviously be unique for each country.
Therefore, as I could not expect to have all the time needed to do the exercise for all the 27 EU Member States, monitored the approach adopted by Brussels.
As I wrote in previous articles, gradually there was a convergence toward a "format", e.g. press announces from Brussels at each presentation by each Member State of a national recovery and resilience plan started showing the same information, ditto for the results of each assessment.
Brussels therefore "harmonized" data from each EU Member State toward a comparable format (while retaining the cross-reference to Member State-specific information and the source material provided).
Hence, all the "number and timeline"-based datasets that I released as discussion basis for the Italian PNRR could, if you are interested, be used as a "template" where to fill the data from other countries.
Obviously, if I will have time, will extend the datasets to the other 27 EU Member States- but if you have time to replicate the process for another EU Member State, drop me a line, and I will create a "links" page where I will credit all the sources and additional datasets.
What's new in that PNRR-related dataset on funding and coverage
Now, what will you find in the updated version of the Italy's PNRR - funding and coverage / funding timeline from the European Council assessment as of 2021-07-08 dataset?
I would just give you a hint through a picture and a table:
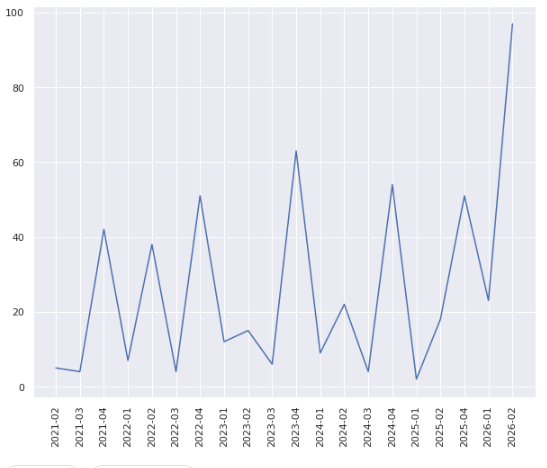
If you prefer to see the information as a table:
2021-02 5
2021-03 4
2021-04 42
2022-01 7
2022-02 38
2022-03 4
2022-04 51
2023-01 12
2023-02 15
2023-03 6
2023-04 63
2024-01 9
2024-02 22
2024-03 4
2024-04 54
2025-01 2
2025-02 18
2025-04 51
2026-01 23
2026-02 97
What you see above is how many of the 527 items identified and assessed by Brussels within the Italian #PNRR and associated documentation have a target within each quarter.
You can reuse the data or create your own visualizations, and as a free resource online to get you started use this Jupyter Notebook on Kaggle that added yesterday.
The information contained within the dataset is the following:
_MissionsTimelineTargetReferences.csv - for each of the 527 reference numbers, contains the target deadline for completion and the page within the document where it is outlined
_MissionsTimelineCoverage.csv - for each of the 527 reference numbers, contains the grant or loan instalment whose funding covers it
_MissionsTimelineFunding.csv - for each one of the 10 grant and 10 loan instalments, the amount assessed as of 2021-07-08
_Timeline.csv - for each of the 527 reference numbers, contains the timeline and association with the grant or loan instalment, as 2021-07-08
Where are we now on the path to the implementation of the PNRR
Today's "Il Sole 24 Ore" reported that "The [Italian] Government allocated just half of the PNRR funding":

As this article is within the "CitizenAudit" series, focused on sharing, I will share in a future article my commentary.
Humble suggestions for others interested in observing PNRR delivery
If you are a specialist in a specific area but are not used to track "compliance" and "risk" through the years, I would suggest, if you want to replicate the datasets for another EU Member State, to consider it as a kind of "mandatory compliance" project, such as the introduction of GDPR compliance.
Meaning: you start from the target date, and plan in reverse (both for the national recovery and resilience plan and for your own project number crunching it), then be realistic about what you can do- and what you can go "minimalistic" on (i.e. which corners you can cut in your dataset preparation).
If you have a team, you will obviously also have to consider roles and coherence in approach- in such cases, my favorite is to define a "format", more than a project charter,; as for the team management, adopt the approach that you prefer- personally, I go "lean": if it worked even in the Army in my own specific area, can work elsewhere- it is just a matter of thinking on the same page.
If you are a solo analyst or specialist by training and experience, it might well be that, in other cases, you are inclined to be a perfectionist.
In a case such as this one, you can start aiming for the "full Monty", i.e. implement everything to the letter, including optional (just to avoid missing something).
But the actual plan to execute your project (in this case, adapting the datasets to another country) should be realistic if you want it to be complete.
If you set targets that are perfectionist but unrealistic, you risk not completing anything.
And, also in compliance with regulations etc, usually you can see a reference to levels of compliance: so, why not for your own data project?
In my case, walked the talk (I know- formally is walk the walk, talk the talk- but I prefer it my way): went across the documentation, identified those documents that could be a "replicable format", went browsing through them cover to cover, identified the key elements that would need, and then started reading again the documents focusing on the parts I had chosen.
Finally, extracted the data, and then went through the usual exploration activities to select and structure (I will skip listing the tools that I used).
I already shared other articles on #NextGenerationEU where I actually selectively used extracts from those documents, charts, etc- just search this website.
If you have time and/or interest, as an introduction on building up and carrying out a similar project, have a look at a book I published few years ago, #QuPlan - A Quantum of Planning (yes, it is free online)- and it contains also a fictional business case across a "miniseries" (basically, the mini-book is much shorter than the fictional business case).
Next steps: the end of the beginning
As soon as I will have had few iterations and tried maybe to apply the approach to another couple of countries ("couple" as in "paar" in Dutch- not two, but a few), I will maybe publish something describing end-to-end the approach applied to the #NextGenerationEU, as anyway future European Commission disbursements will probably follow a similar approach.
I posted today on Linkedin:

So, if you have any suggestion or, after trying to see the data, you see something missing (or just amiss), let m know.
But, for the time being, this article is already over 2,500 words.
Enjoy the data!